HashMap的实现原理详解 | 陈加成
本文将从数据结构的角度引入 "哈希表" 这一概念。
1. 从数据结构的角度理解哈希表
基本思想: 以线性表中的每个元素的关键字 key 为自变量,通过一种函数 H(key) 计算出函数值,把这个函数值解释为一块连续存储空间的单元地址(即下标),将该元素存储到这个单元中。
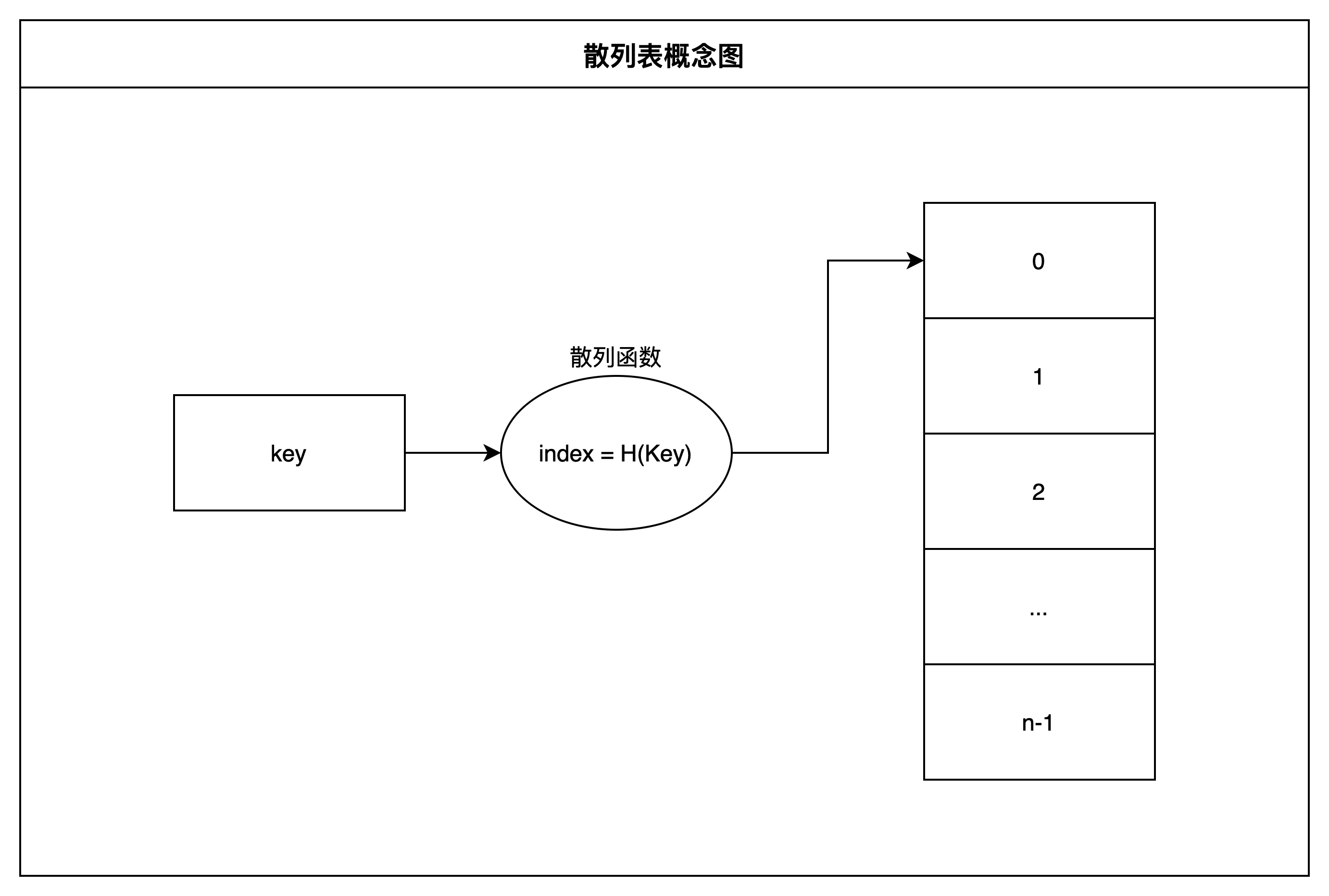
散列存储中使用的函数 H(key) 称散列函数或哈希函数,实现关键字到存储地址的映射(或转换)。
哈希冲突是什么?
当散列函数 H(key) 将两个或以上不同的key映射为同一个索引时,就发生了哈希冲突。
冲突的频率除了与散列函数相关外,还与散列表的填满程度相关。
设 m 为散列表表长,n为表中填入的元素数量,将 α = n/m 定义为散列表的负载因子,那么,α 越大,表装填的越满,冲突发生的机会就越大。
如何尽量避免冲突和冲突发生后如何解决冲突,就是散列存储的两个关键问题。
1.2 散列函数
构造散列函数的目标是使散列地址尽可能均匀地分布在散列空间上,同时使计算尽可能简单。
1. 直接地址法
直接地址法是以关键字 key 本身或关键字加上某个常量 C 作为散列地址的方法。
对应的散列函数 H(key) 为: H(key) = key + C
在使用时,为了使散列地址与存储空间吻合,可以调整 C。这种方法计算简单,并且没有冲突。它适合关键字的分布基本连续的情况,若关键字分布不连续,空号较多,将会造成较大的空间浪费。
Java中 Character\Byte\Short\Integer的散列函数使用了这个方法。可理解为 H(key) = key+0。
2. 数字分析法
数字分析法是假设有一组关键字,每个关键字由 n 位数字组成,如 k1,k2,...,kn。数字分析法是从中提取数字分布均匀的若干位作为散列地址。
3. 除余数法
除余数法是选择一个适当的 p(p<=散列表长m)取出关键字k,所得余数作为散列地址的方法。
对应的散列函数为: H(key) = key% p;
4. 平方取中法
平方取中法是取关键字平方的中间几位作为散列地址的方法,因为一个乘积的中间几位和乘数的每一位都相关,故由此产生的散列地址较为均匀,具体取多少位视情况而定。
5. 折叠法
折叠法是首先把关键字分割成位数相同的几段,段的位数取决于散列地址的位数,由实际情况而定,然后将它们叠加和(舍去最高近位),作为散列地址的方法。
折叠法又分移位叠加和边界叠加,移位叠加是将各段的最低位对齐,然后相加;边界叠加则是将两个相邻的段沿边界来回折叠,然后对齐相加。
Java中的散列函数大致可分三类,Object中的系统默认实现,各包装数据类型的实现,自定义对象的自定义实现。
1.3 处理冲突的办法
散列法构造表可通过散列函数的选取来减少冲突,但冲突一般不可避免,为此,需要有解决冲突的方法。常用的解决冲突的方法有两大类,即开放定址法和拉链法。
1. 开放定址法
开放定址法又分为线性探查法、二次探查法和双重散列法。
开放定址法解决冲突的基本思想是: 使用某种方法在散列表中形成一个探查序列,沿着此序列逐个单元进行查找,直到找到一个空闲的单元时将新节点存入其中。
2. 拉链法(链地址法)
当存储结构是链表时,多采用拉链法。用拉链法处理冲突的办法是:把具有相同散列地址的关键字(同义词) 值放在同一个单链表中,称为同义词链表。
有m个散列地址就有m个链表,同时使用指针数组 T[0..m-1] 存放各个链表的头指针,凡时散列地址为i的记录都以节点方式插入到以T[i]为指针的单链表中。T中各分量的初值应为空指针。
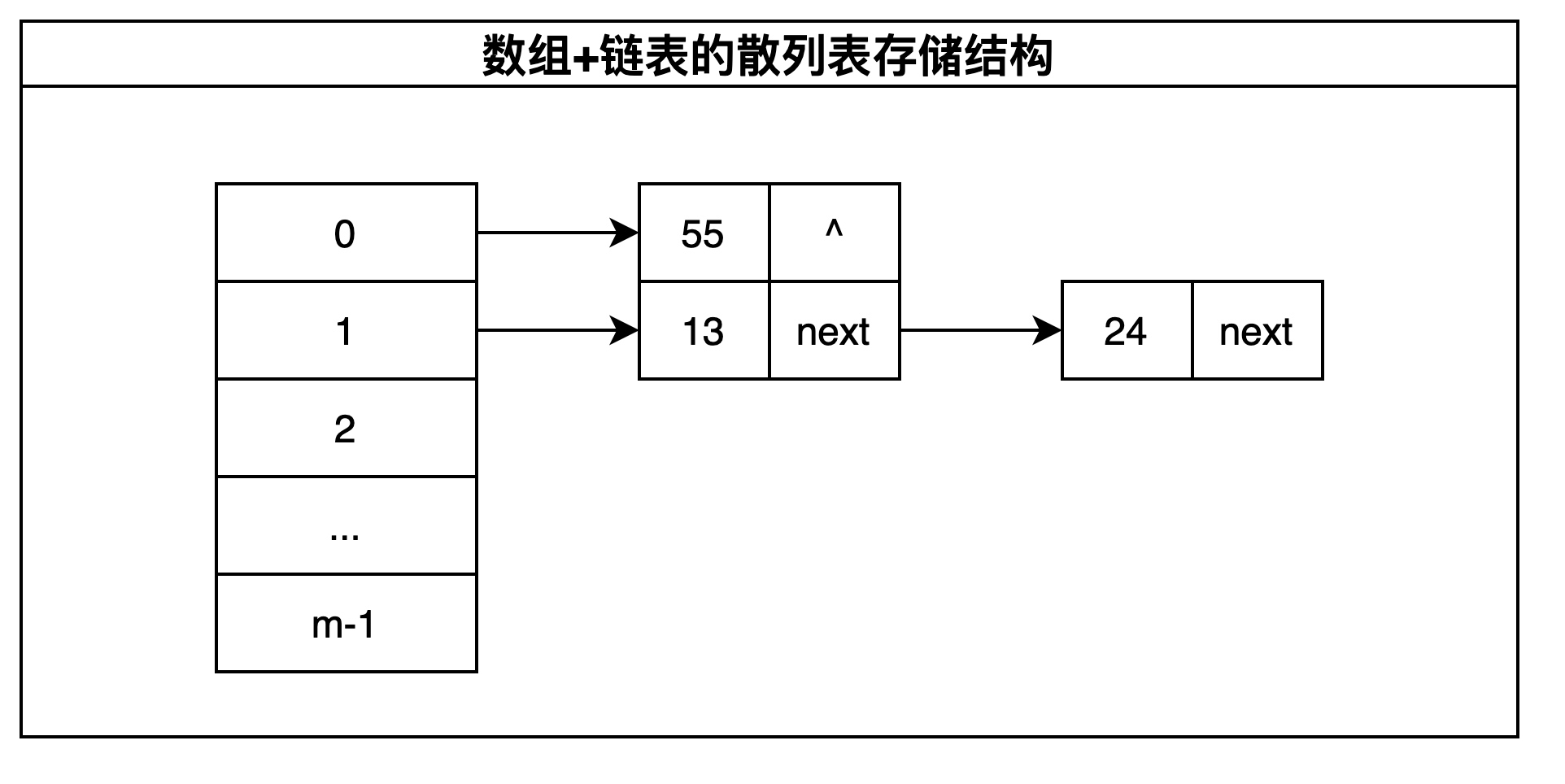
平均查找数较少,因为查找的只有同义词节点,而开放定址法是查找所有节点。
1.4 散列表的查找
1. 线性探查法解决冲突的查找和插入算法
查找: 根据散列函数找到对应的节点,然后比对元素是否相同,循环一周若无相同元素则返回。
插入: 根据散列函数找到对应的节点,若空,直接插入,非空,则循环查找下一个空位置。
2. 拉链法建立散列表上的查找和插入运算
查找: 根据散列函数找到对应的节点,然后顺链查找。
插入: 根据散列函数找到对应的节点,在节点上添加新链接。
2. Java 的 HashMap 的实现
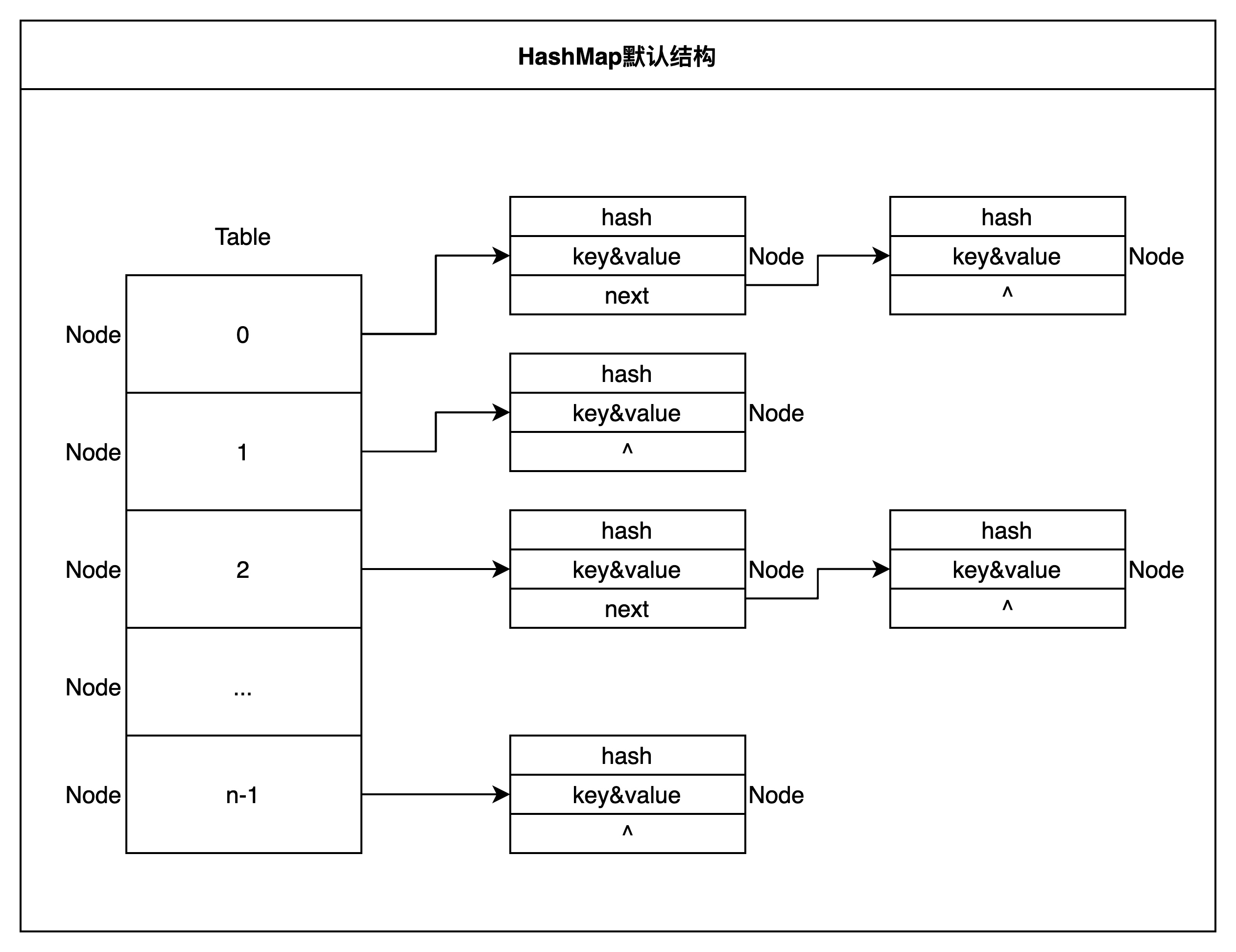
2.1 HashMap存储结构
JDK8之前: 数组+链表
JDK8和之后: 数组+链表,若链表长度超过8,则将其树化为红黑树
2.2 散列函数-hashCode
Object对象默认散列函数:
1. OpenJDK: OpenJDK8基于线程状态的随机算法生成的随机数。
2. HotSpot: 在HotSpot中,身份哈希生成的结果一次生成,并缓存在对象头的标记字中。
各基本数据类型包装类: 能自动转型为int的直接转型,否则将转换为int表示的位。
自定义对象: 自行实现。
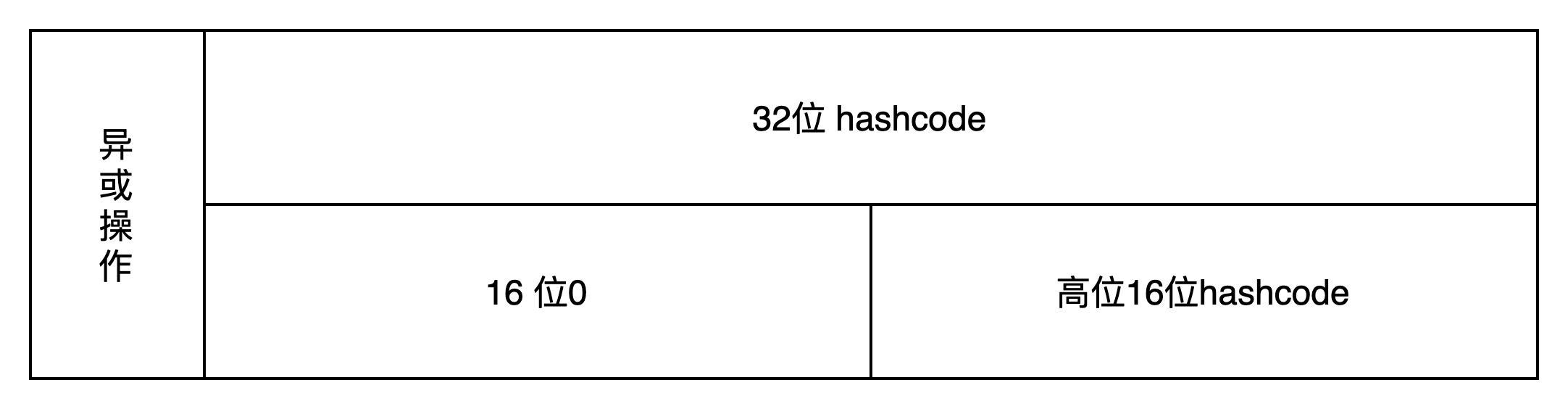
Hash::hashCode: 使用扰动函数,可以看作是一种折叠函数,将32位的bit位一分为二,并进行异或操作,使得散列函数表示的位更加分散。
扰动函数: (h = key.hashCode()) ^ (h >>> 16);
2.3 如何处理冲突
使用拉链法: 数组+链表,使用散列函数获取对应索引,然后在索引对应的节点上进行插入链接或查找操作。
插入元素时,如果链表长度超过阈值则进行树化操作。
2.4 查找和插入具体实现
查找: 根据散列函数找到对应的节点,如果该节点是树节点,则调用红黑树的查找算法进行查找,否则顺链查找。
插入: 根据散列函数找到对应的节点,在节点上添加新链接。
1. 检查容器是否为空,为空则创建容器。
2. 检查对应的节点是否为空,为空则直接添加新节点。
3. 检查头节点的hash是否与添加的节点相同,相同则替换旧值。
4. 检查头节点类型是否是TreeNode,如果是则使用红黑树的插入算法。
5. 按链进行循环查找同义词尾部节点,如果为空,添加新节点到尾部的next节点,如果链表长度大于或者等于阈值8则进行树化操作。如果该节点的key与新增key相同则进行替换。
6. 最后,如果当前容量超过阈值则直接进行resize2.5 树和二叉树和平衡二叉树和红黑树
树是一个通用的数据结构,可以有多种类型。
二叉树是树的一种特殊形式,每个节点最多有两个子节点。
平衡二叉树是一种特殊的二叉树,保持平衡以提高性能。
红黑树是一种常见的平衡二叉树,具有自平衡性质,用于高效地支持插入、删除和查找等操作。
3. 面试题
3.1 并发修改导致的循环引用
插入和删除都会修改链表结构的指针,当多个线程对链表结构的指针进行操作,可能会导致循环引用。理论上会出现,实际上不一定出现,但并发编程只要有能导致不安全理论的存在,就一定会出现不安全的现象。
OpenJDK: Object::hashCode函数的底层实现: https://srvaroa.github.io/jvm/java/openjdk/biased-locking/2017/01/30/hashCode.html